梯度下降法
梯度下降法(英語:Gradient descent)是一個一階最佳化算法,通常也稱為最陡下降法,但是不該與近似積分的最陡下降法(英語:Method of steepest descent)混淆。 要使用梯度下降法找到一個函數的局部極小值,必須向函數上當前點對應梯度(或者是近似梯度)的反方向的規定步長距離點進行疊代搜索。如果相反地向梯度正方向疊代進行搜索,則會接近函數的局部極大值點;這個過程則被稱為梯度上升法。
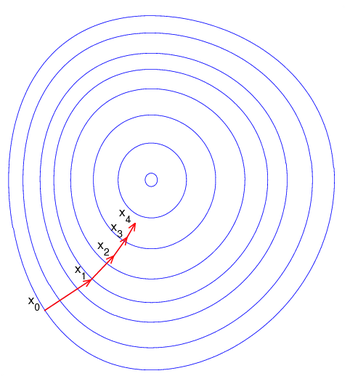
既然在變量空間的某一點處,函數沿梯度方向具有最大的變化率,那麼在優化目標函數的時候,自然是沿著負梯度方向去減小函數值,以此達到我們的優化目標。
如何沿著負梯度方向減小函數值呢?既然梯度是偏導數的集合,如下:
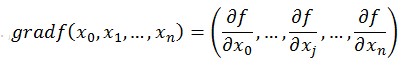
同時梯度和偏導數都是向量,那麼參考向量運算法則,我們在每個變量軸上減小對應變量值即可,梯度下降法可以描述如下:
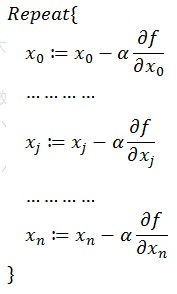
描述

甚麼是梯度消失
梯度是一種數學概念,用於描述一個函數的變化率。在機器學習中,我們會使用梯度下降法來最小化損失函數。
損失函數是用來衡量模型預測結果與實際結果之間的差異的函數。通過最小化損失函數,我們可以讓模型的預測結果越來越接近實際結果。
梯度下降法是一種基於梯度的最優化算法,它會不斷計算損失函數的梯度,並根據梯度的大小和方向來更新模型的參數。當梯度越大,就意味著模型的預測結果與實際結果的差異越大,所以需要更大的步長來進行更新。當梯度越小,就意味著模型的預測結果與實際結果的差異越小,所以可以使用較小的步長來進行更新。
隨著層數的增加,梯度有可能會越來越小。這是因為在深度神經網路中,每個層的輸入都是前一層的輸出,因此如果前一層的輸出有變化,那麼這層的輸入也會有變化。如果前一層的輸出有很大的變化,那麼這層的輸入也有可能有很大的變化,導致梯度變小。而如果前一層的輸出沒有太大變化,那麼這層的輸入也不會有太大變化,梯度就不會變小。
當梯度變得非常小時,梯度下降法就無法有效地更新模型的參數、有可能陷入局部最小值,使得模型無法有效地學習。
這就是深度神經網路中的梯度消失問題。殘差網路就是為了解決這個問題而設計的。這是因為梯度下降法是通過梯度的大小和方向來決定步長的,如果梯度變得非常小,那麼步長也會變得非常小,導致更新參數的幅度非常小。
這篇文章對梯度下降法有很詳細的解釋: https://ithelp.ithome.com.tw/articles/10273302
更多關於CNN殘差學習介紹: https://zhuanlan.zhihu.com/p/31852747