什麼是Function calling
官方介紹文檔:https://platform.openai.com/docs/actions/introduction
中文介紹文檔:https://openai.xiniushu.com/docs/plugins/getting-started
Function calling是一種技術,允許LLM根據對話內容自主選擇並調用預定義的函數。這些函數可以用來執行各種任務,例如查詢實時數據、執行計算、生成圖像等。函數調用是建立 LLM 驅動的聊天機器人或代理(agents)的重要能力,這些聊天機器人或代理需要檢索 LLM 的上下文或通過將自然語言轉換為 API 調用來與外部工具互動。
功能調用使開發者能夠創建:
- 用戶提示:用戶輸入一個查詢或命令,LLM識別出需要調用特定函數。
- 函數觸發:LLM解析輸入內容,並確定需要調用的函數。
- 函數執行:LLM生成包含函數名稱和參數的JSON對象,並調用相應的函數。
- 響應交付:函數執行後返回結果,LLM處理該結果並以可理解的格式交付給用戶
Function Calling可以做到那些事情
- 有效的使用外部工具來回答問題
例如:查詢「伯利茲的天氣怎麼樣?」將被轉換為類似get_current_weather(location: string, unit: 'celsius' | 'fahrenheit')的函數調用。 - 用來提取和標記數據
例如:從維基百科文章中提取人名 - 將自然語言轉換為API調用或者做有效的資料庫查詢的應用程式
- 對話式的知識檢索並與知識庫互動
如何實現function calling
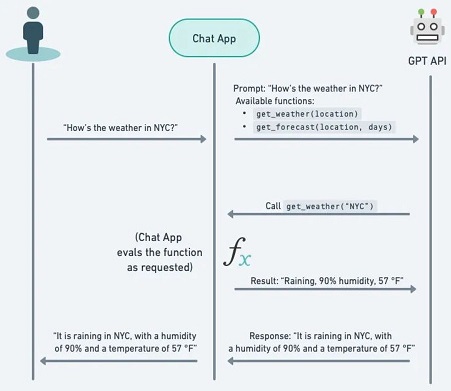
假如我們現在想要詢問某個地點的天氣,一般的LLM無法做到這件事情,因為訓練的數據集不會包括現在的即時數據。解決這個問題的方法是將LLM與外部工具結合。利用模型的Function Calling能力來確定要調用的外部函數及其參數,然後讓它返回最終的回應。
假設一位用戶向模型提出以下問題:
台北市今天的天氣如何
要實現function calling,需要在LLM的接口中註冊函數,並將這些函數的描述和使用說明一同發送給模型。模型會根據上下文智能地選擇並調用適當的函數。以下是一個簡單的實現示例:
這個範例會使用一個公共API:Weather.gov,要獲取預報,有兩個步驟:
- 用戶向 api.weather.gov/points API 提供緯度和經度,並收到 WFO(天氣預報辦公室)、grid-X 和 grid-Y 坐標。
- 這三個元素會輸入到 api.weather.gov/forecast API,以獲取該坐標的天氣預報。

首先,ChatGPT 會使用頂部的 info(特別是描述)來判斷此操作是否與用戶查詢相關。接著定義API的接口和每個接口的功能。
然後,下面的 參數 進一步定義了架構的每個部分。例如,我們正在告訴 ChatGPT,辦公室 參數指的是天氣預報辦公室 (WFO)。
openapi: 3.1.0
info:
title: NWS Weather API
description: Access to weather data including forecasts, alerts, and observations.
version: 1.0.0
servers:
- url: https://api.weather.gov
description: Main API Server
paths:
/points/{latitude},{longitude}:
get:
operationId: getPointData
summary: Get forecast grid endpoints for a specific location
parameters:
- name: latitude
in: path
required: true
schema:
type: number
format: float
description: Latitude of the point
- name: longitude
in: path
required: true
schema:
type: number
format: float
description: Longitude of the point
responses:
'200':
description: Successfully retrieved grid endpoints
content:
application/json:
schema:
type: object
properties:
properties:
type: object
properties:
forecast:
type: string
format: uri
forecastHourly:
type: string
format: uri
forecastGridData:
type: string
format: uri
/gridpoints/{office}/{gridX},{gridY}/forecast:
get:
operationId: getGridpointForecast
summary: Get forecast for a given grid point
parameters:
- name: office
in: path
required: true
schema:
type: string
description: Weather Forecast Office ID
- name: gridX
in: path
required: true
schema:
type: integer
description: X coordinate of the grid
- name: gridY
in: path
required: true
schema:
type: integer
description: Y coordinate of the grid
responses:
'200':
description: Successfully retrieved gridpoint forecast
content:
application/json:
schema:
type: object
properties:
properties:
type: object
properties:
periods:
type: array
items:
type: object
properties:
number:
type: integer
name:
type: string
startTime:
type: string
format: date-time
endTime:
type: string
format: date-time
temperature:
type: integer
temperatureUnit:
type: string
windSpeed:
type: string
windDirection:
type: string
icon:
type: string
format: uri
shortForecast:
type: string
detailedForecast:
type: string
OpenAI很貼心的為我們提供了一個幫我們撰寫此Yaml的機器人
https://chatgpt.com/g/g-TYEliDU6A-actionsgpt
使用方法如下:

在測試API的時候,可以使用Postman來測試上面的OpenAPI架構。Postman 註冊是免費的,錯誤處理詳盡,並且在身份驗證選項上非常全面。它甚至還提供直接導入 Open API 架構的選項(見下文)。

如果要進行身分驗證,可參考以下文章